廣告怎麼下都不受眾?用這些數據玩轉美國版PTT Reddit

首圖來源:elevenews
\n\n原文出自「看廣告主如何用數據分析,玩轉reddit | DT×NYCDSA」,作者Mitchell Hung,本文獲DT財經授權轉載,未經同意請勿轉載\n▍當我研究reddit時,到底在研究什麼\n\n近幾年Reddit越來越火,2014年它的頁面瀏覽數超過700億。根據Alexa的數據,2017年,Reddit是美國瀏覽量第四,全球瀏覽量第七的網站。超過4%的美國成年人使用Reddit,其中67%是男性用戶,他們大多數年齡較輕,在18到35歲之間。\n\n當我們研究Reddit,其實是在研究全世界最大的網民群體之一。更重要的是,Reddit上佔統治地位的用戶群體也是互聯網最具價值的目標群體:18歲到35歲之間的男性。對於所有未來的廣告主,Reddit是一個名副其實的信息金礦,瞭解其用戶和內容的特徵是勢在必行的任務。\n\n \n\n所以,我主要我帶著兩個較為寬泛的問題展開研究:\n
- \n
- 我們可以從Reddit的用戶行為以及網站結構觀察到哪些行為範式? \n
- \n
- 從市場營銷的角度,在Reddit上做廣告的最佳方式是什麼? \n
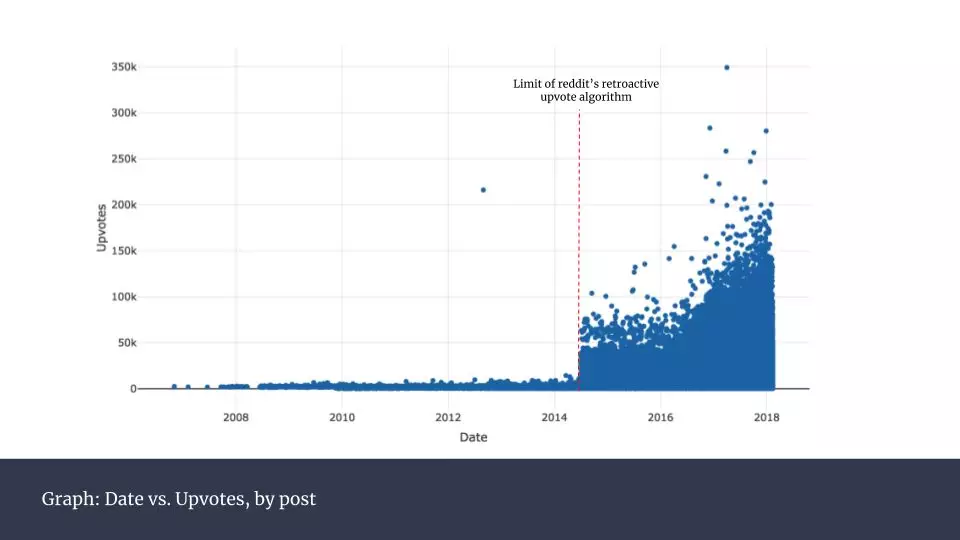 \n\n在圖中可以看到一個明顯的人為干預產生的「突變」。在圖中所示2014年年中的地方,我做出了標記。2016年12月,Reddit宣佈採用一種改良的方法來計算點贊數。點贊數不再是簡單的加總,而是經過一個黑箱算法處理過後的數據。這個算法的原理並未公開,因此只有最終顯示出的這些數字可以用來分析。無論如何,Reddit方面表示,這樣做的目的是為了更好地反映真實的點贊情況。\n\n在實踐中我們可以看到,這樣的變化的確大幅提升了點贊數。但從圖中可以看出,這樣的改變對過往數據的影響方面,僅僅在特定日期(2014年6月29日)出現巨大變動。為了保證之後分析的可信度,我嘗試對沒有受到點贊統計規則影響的數據進行修正,效果如下:\n\n
\n\n在圖中可以看到一個明顯的人為干預產生的「突變」。在圖中所示2014年年中的地方,我做出了標記。2016年12月,Reddit宣佈採用一種改良的方法來計算點贊數。點贊數不再是簡單的加總,而是經過一個黑箱算法處理過後的數據。這個算法的原理並未公開,因此只有最終顯示出的這些數字可以用來分析。無論如何,Reddit方面表示,這樣做的目的是為了更好地反映真實的點贊情況。\n\n在實踐中我們可以看到,這樣的變化的確大幅提升了點贊數。但從圖中可以看出,這樣的改變對過往數據的影響方面,僅僅在特定日期(2014年6月29日)出現巨大變動。為了保證之後分析的可信度,我嘗試對沒有受到點贊統計規則影響的數據進行修正,效果如下:\n\n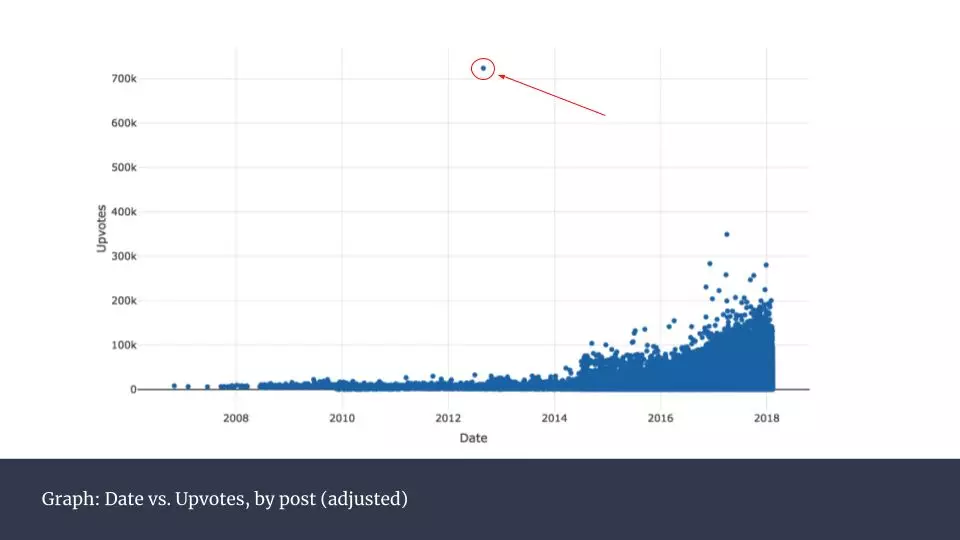 \n\n這樣操作後,整個數據集的變化更加平滑。你可能會發現2012年出現過一個極端的點,我用紅色標示出來。這並不是出錯了,它是當年美國總統奧巴馬參加的一個熱門問答貼。\n\n出於一探優秀用戶行為習慣的好奇,我接下來對100個最有名用戶的點贊數進行可視化。\n\n
\n\n這樣操作後,整個數據集的變化更加平滑。你可能會發現2012年出現過一個極端的點,我用紅色標示出來。這並不是出錯了,它是當年美國總統奧巴馬參加的一個熱門問答貼。\n\n出於一探優秀用戶行為習慣的好奇,我接下來對100個最有名用戶的點贊數進行可視化。\n\n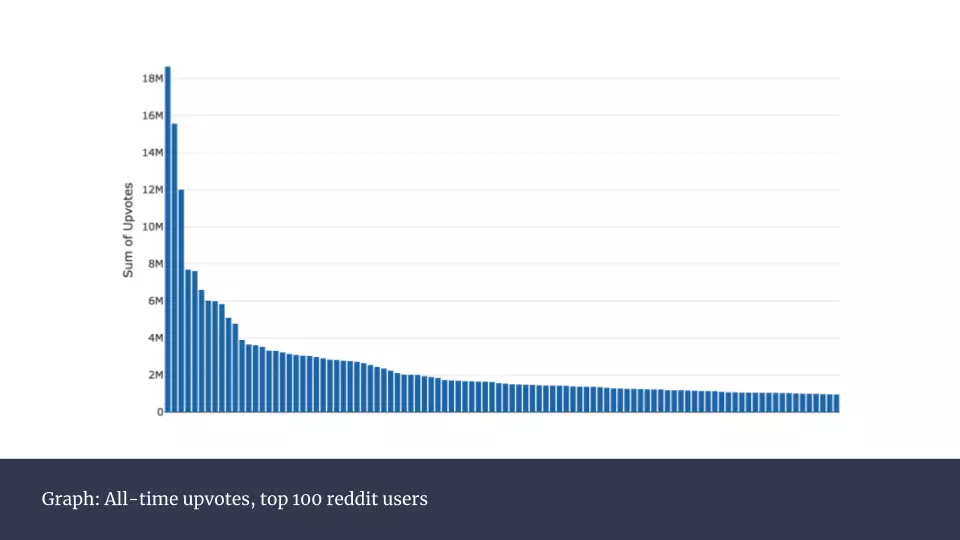 \n\n這是一個非常頭重腳輕的分布。其實,前100名用戶佔了全部12%的點贊數。考慮到2017年Reddit已經有超過16億獨立訪客,這顯得非常不平衡。而這也揭示出這些頭部用戶的發帖方式與其他普通用戶肯定有很大不同。接下來我們就來研究這些成功的帖子背後有哪些特徵。\n\n
\n\n這是一個非常頭重腳輕的分布。其實,前100名用戶佔了全部12%的點贊數。考慮到2017年Reddit已經有超過16億獨立訪客,這顯得非常不平衡。而這也揭示出這些頭部用戶的發帖方式與其他普通用戶肯定有很大不同。接下來我們就來研究這些成功的帖子背後有哪些特徵。\n\n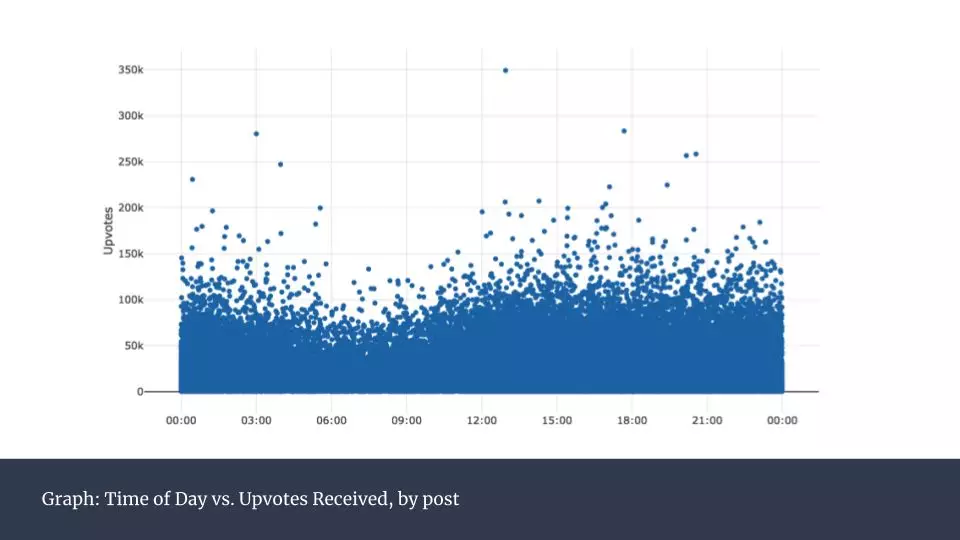 \n\n上圖是所有帖子在一天內的發帖時間的分類統計,可以看到0點到12點之間呈下滑走勢。而這之後,平均數保持平穩。按照星期來統計(下圖),則沒有發現任何規律。\n\n
\n\n上圖是所有帖子在一天內的發帖時間的分類統計,可以看到0點到12點之間呈下滑走勢。而這之後,平均數保持平穩。按照星期來統計(下圖),則沒有發現任何規律。\n\n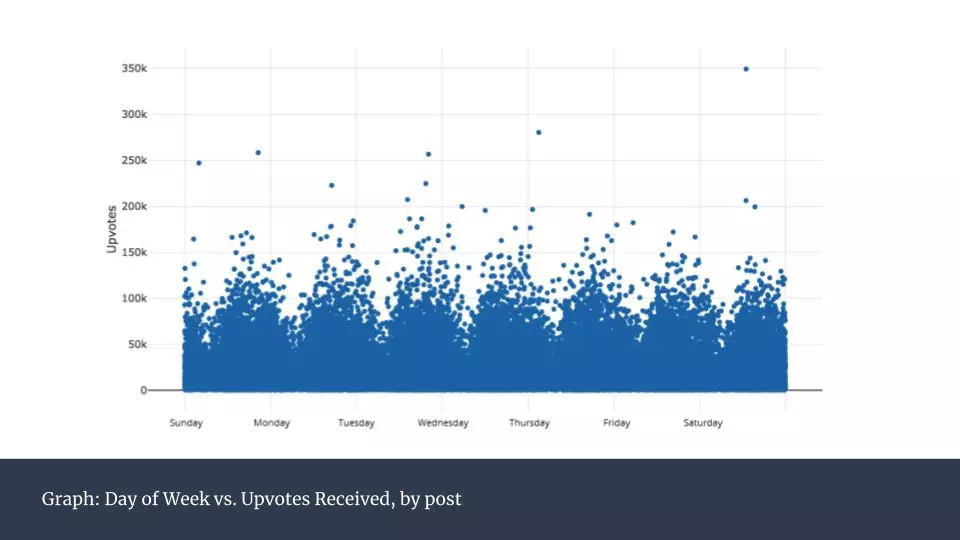 \n\n接下來我對獲得點贊最多的帖子中包含的鏈接所對應的域名進行分析,將每一個域名的全部點贊數加總呈現在下圖。\n\n
\n\n接下來我對獲得點贊最多的帖子中包含的鏈接所對應的域名進行分析,將每一個域名的全部點贊數加總呈現在下圖。\n\n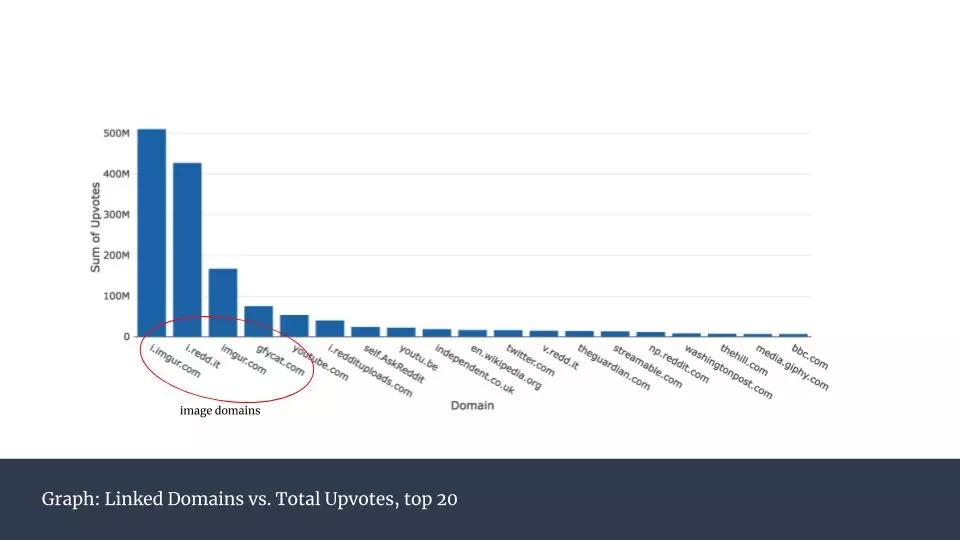 \n\n
\n\n


