暨圍棋後,AlphaGo玩迷宮遊戲 已具人類通關技巧!

首圖來源:315hi
自從在圍棋上成功碾壓人類(主要是李世石)之後,Google 旗下深度學習產品團隊 DeepMind 又開始讓 AlphaGo 學習怎麼玩遊戲,而且在極具挑戰性的三度空間迷宮遊戲 Labyrinth 中,取得了人類玩遊戲的水準。

據 Google 黑板報介紹,DeepMind 的目標是「創造出一個能通過自我學習去製定戰略,並最終取得出色的成績的人工代理(artificial agents)。而在玩遊戲的背後,是對於機器學習中深度強化學習的不斷探索。」
所謂「深度強化學習」是「深度學習」加上「深度強化」,也就是說在經過無數次試驗、在錯誤和正確中不斷鍛煉的強化學習的過程中,再加上深度學習的過程;其中,深度學習則是直接通過原始輸入,自行構造並學習指示的過程。
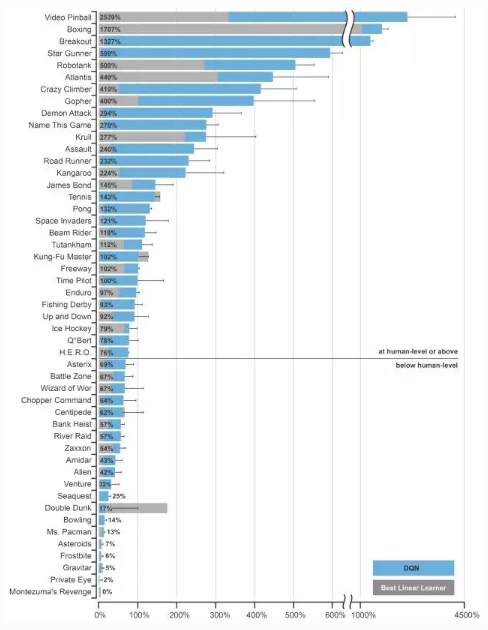
早在兩年前,DeepMind 在《自然》上發表的文章中就已經讓AlphaGo有很厲害的遊戲水準了,在訓練AlphaGo玩遊戲的時候用了名叫 DQN (Convolutional Neutral Network + RL) 的深度強化學習算法,通過 50 種不同的雅達利遊戲 (Atari) 來訓練AlphaGo的能力,結果表明 Google 的人工智慧軟體在雅達利 2600 的測試中,在 49 個遊戲中有 29 個遊戲獲得了75% 的專業測試的成績,已經到了人類的水準。
雅達利 2600 是美國的一個經典遊戲機,當中經典的遊戲包括Adventure、碰碰彈子台、爆破彗星和Pac-Man等。
現在 Google 又通過穩定學習動態等多種方式改進了 DQN 算法,使該算法在雅達利遊戲的平均得分提高了 300%。現在人工代理已經在幾乎所有雅加達遊戲中取得了人類水平,單一神經網路甚至可以被培訓去掌握多種雅達利遊戲。
據 Google 介紹,與此同時,名為 Gorila 的大型分布式深度強化學習系統也誕生了,這個系統利用 Google Cloud 平台,使代理的學習速度提高了一個等級。這讓AlphaGo的遊戲水準更加深了一步,可以挑戰極具挑戰性的 3D 導航和迷宮環境,通過直接視野裡觀察到的像素輸入,人工代理依此畫出地圖以發現並找到遊戲的通關法則。
迷宮 (Labyrinth) 就是AlphaGo最新征服的遊戲,Google 會在未來幾個月以開源的形式發布。
文章來源:TECH2IPO / 創見,轉載請註明出處。


