Google翻譯不再卡卡的!機器學習結合大數據讓人工智慧成真?

在 AlphaGo 打敗世界棋王李世石後,人工智慧彷彿一項突然間就要從科幻電影中走出的真實科技,成為引起大家高度關注的話題,不過其實早在 2014 年開始,投資在 AI 人工智慧上的金額就開始倍增,以現在科技成指數性進步的速度來看,成熟的人工智慧應用似乎指日可待,然而這項技術究竟離現在的我們還有多遠的距離,也許可以從 Google 翻譯導入神經網路的進展看出一些端倪。
過去的 Google 翻譯運作模式,假設要將中文翻成西班牙文,傳統的翻譯模型會先將中文轉換為英文,再將英文轉換為目標語言也就是西班牙文,由於中間經過了兩次的轉換,因此容易造成雜訊被放大,語句偏離原意的情況發生,此外系統轉換語意時是以單字到單字的方式進行,儘管每個單字幾乎都能夠正確被翻譯,但拼湊起來卻會變成語句不通順又看不懂的句子,這也是為什麼過去我們可以很輕易的看出一段文字是 Google 翻譯的結果還是人工的翻譯。
以傳統的 Google 翻譯來說,我們很容易得到一段莫名其妙的翻譯結果,舉例來說我們以川普的一小段演說詞為例:
We will build new roads, and highways, and bridges, and airports, and tunnels, and railways all across our wonderful nation.
We will get our people off of welfare and back to work - rebuilding our country with American hands and American labor.
透過過去的翻譯演算模型,我們會得到下面的結果:
我們將建設新的道路和公路,橋梁,機場,隧道和鐵路所有在我們美好的國家。
我們將讓我們的人民過福利和恢復工作,重建我們的國家與美國的雙手和美國勞工。
然而,如同上面的翻譯結果,Google 翻譯過往低落的品質是遭人詬病的主要原因,根據官方的資料表示,全世界有大約 50% 的網路內容是以英文呈現,全球卻只有 20% 的使用者是以英語為其主要語言,每月使用 Google 翻譯的使用者超過 10 億人,代表每 3 個網路使用者當中就有 1 個人是 Google 翻譯的活躍使用者,Google 光是一天就要進行超過 10 億次的翻譯行為,這也是為什麼 Google 要如此重視他們的翻譯功能。

不過,經由導入神經網路後的 Google 翻譯,可以發現透過這項技術明顯提升了得到的成果:
我們將在美好的國家建設新的道路,高速公路,橋樑,機場,隧道和鐵路。
我們將讓我們的人民擺脫福利,重返工作 - 用美國的手和美國勞工重建我們的國家。
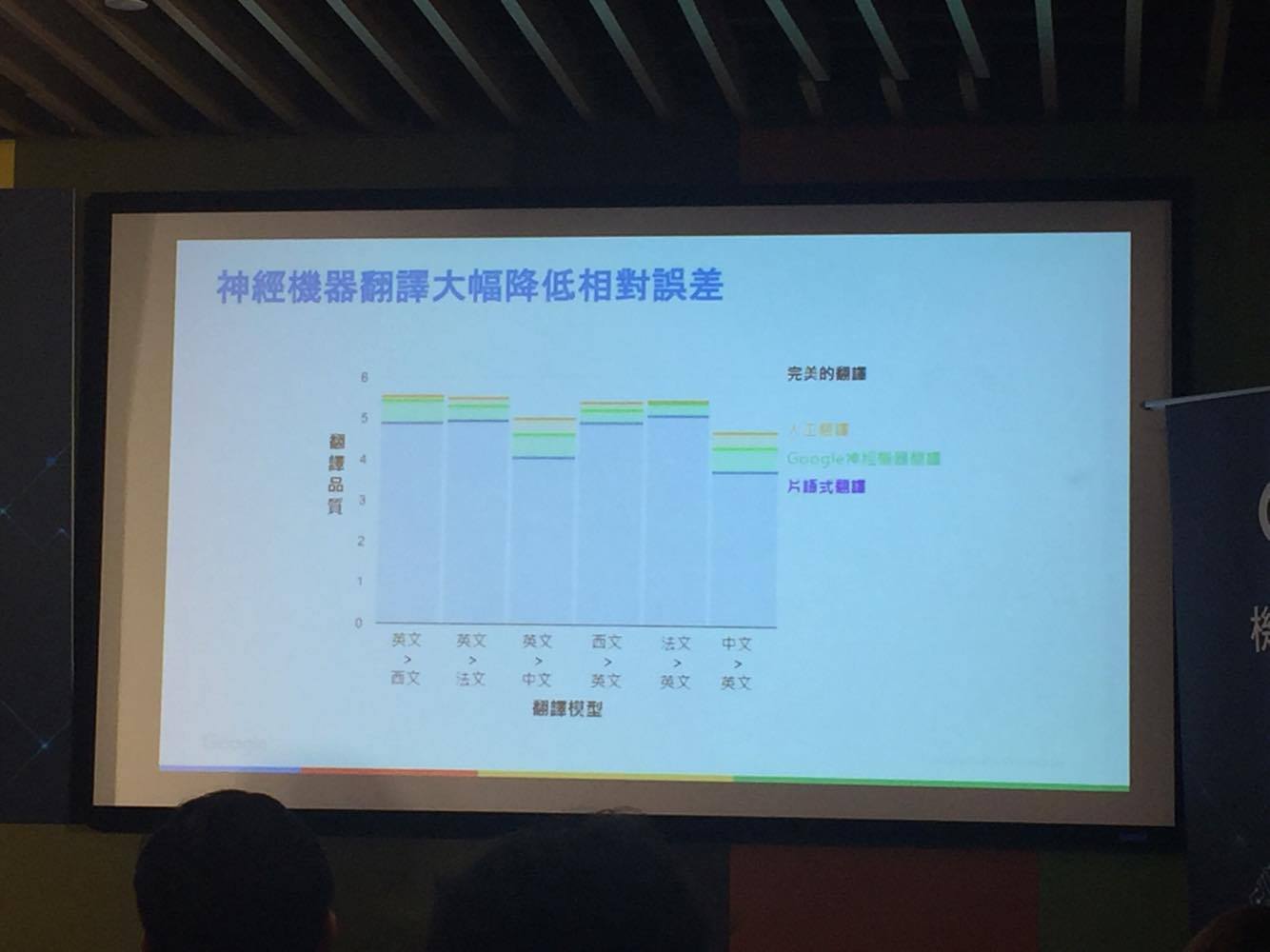
如果說傳統的翻譯模式是片語式的翻譯,導入神經網路後的翻譯系統就如同類比訊號一樣,是連續且全面的,每一個單字片語從傳統翻譯判定沒有關聯的情形下,開始建立了前後文彼此影響的關係,也就是說擁有了類似人類的推理能力,透過這樣的轉變,雖然與人工翻譯的品質仍然存在一段落差,不過相較於傳統片語式的翻譯,可以說是大幅降低了相對誤差。
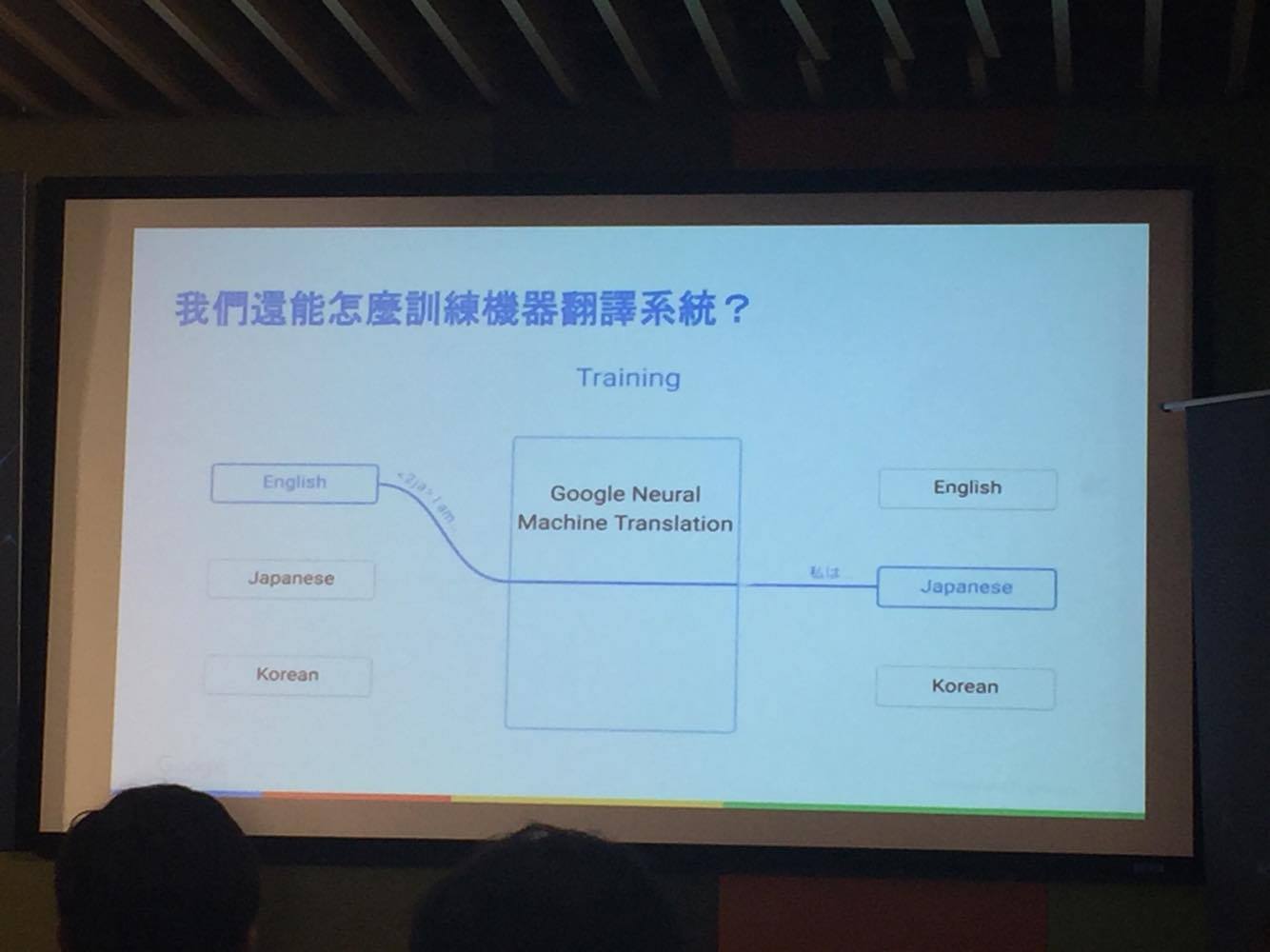
深度學習是人工智慧中成長最快速的一個領域,Google 的神經網路翻譯也是運用這樣的一個概念,每一個翻譯模型並非是自然產生而成,而是需要透過學習,餵養大量的資料與訓練時間才能逐漸完善,不同的語言經過學習之後會轉換成系統容易理解的中間介質語言,因此將兩種語言經過訓練自動學習後,不需要額外的訓練就能自動翻譯另外一種全新的語言。
以 Google 來說平均一個翻譯模型需要 2 至 3 週的訓練時間,所需餵養的資料量則超過 1 億筆,而這樣的學習模式讓資料量成了深度學習中另一個重要的關鍵因素。
舉例來說,相較於英文翻譯成中文,英文翻譯成法文的準確度要來的高許多,這是因為英國與法國從多年前以來就是雙語並行的國家,因此擁有許多正確可用的資料,反觀英文與中文的可用資料就相對較少,不過近幾年來社群網路的蓬勃發展,慢慢解決了資料量上的問題,現在更重要的是蒐集資料的方法,如何從巨量資料中分辨出雜訊與訊號成了最重要的事情。
以人類的演化情形來看大約每千年會進到下一個階段,而摩爾定律告訴我們電腦的運算能力大約每兩年會成長一倍,巨量資料雖然帶來了更多的可能性,同時卻也產生了更多的雜訊,如同人類史上第一次的資訊革命印刷術的誕生一樣,雖然讓知識存量快速累積,但這些資訊的品質差異也十分的大,如果我們能有一套正確分辨雜訊與資訊的系統,相信以 Google 透過神經網路成功改善翻譯品質的案例來看,更成熟的人工智慧或許就離我們不遠了。
image source:Google 提供
過去的 Google 翻譯運作模式,假設要將中文翻成西班牙文,傳統的翻譯模型會先將中文轉換為英文,再將英文轉換為目標語言也就是西班牙文,由於中間經過了兩次的轉換,因此容易造成雜訊被放大,語句偏離原意的情況發生,此外系統轉換語意時是以單字到單字的方式進行,儘管每個單字幾乎都能夠正確被翻譯,但拼湊起來卻會變成語句不通順又看不懂的句子,這也是為什麼過去我們可以很輕易的看出一段文字是 Google 翻譯的結果還是人工的翻譯。
要判斷一項技術是否為成熟的人工智慧,只要看你是否能分辨這是機器還是人做的,當你無法分不出來是機器還是人,這就是一項成熟的人工智慧。
以傳統的 Google 翻譯來說,我們很容易得到一段莫名其妙的翻譯結果,舉例來說我們以川普的一小段演說詞為例:
We will build new roads, and highways, and bridges, and airports, and tunnels, and railways all across our wonderful nation.
We will get our people off of welfare and back to work - rebuilding our country with American hands and American labor.
透過過去的翻譯演算模型,我們會得到下面的結果:
我們將建設新的道路和公路,橋梁,機場,隧道和鐵路所有在我們美好的國家。
我們將讓我們的人民過福利和恢復工作,重建我們的國家與美國的雙手和美國勞工。
然而,如同上面的翻譯結果,Google 翻譯過往低落的品質是遭人詬病的主要原因,根據官方的資料表示,全世界有大約 50% 的網路內容是以英文呈現,全球卻只有 20% 的使用者是以英語為其主要語言,每月使用 Google 翻譯的使用者超過 10 億人,代表每 3 個網路使用者當中就有 1 個人是 Google 翻譯的活躍使用者,Google 光是一天就要進行超過 10 億次的翻譯行為,這也是為什麼 Google 要如此重視他們的翻譯功能。
image source:網路溫度計/記者 葛緯詩攝
不過,經由導入神經網路後的 Google 翻譯,可以發現透過這項技術明顯提升了得到的成果:
我們將在美好的國家建設新的道路,高速公路,橋樑,機場,隧道和鐵路。
我們將讓我們的人民擺脫福利,重返工作 - 用美國的手和美國勞工重建我們的國家。
如果說傳統的翻譯模式是片語式的翻譯,導入神經網路後的翻譯系統就如同類比訊號一樣,是連續且全面的,每一個單字片語從傳統翻譯判定沒有關聯的情形下,開始建立了前後文彼此影響的關係,也就是說擁有了類似人類的推理能力,透過這樣的轉變,雖然與人工翻譯的品質仍然存在一段落差,不過相較於傳統片語式的翻譯,可以說是大幅降低了相對誤差。
image source:網路溫度計/記者 葛緯詩攝
深度學習是人工智慧中成長最快速的一個領域,Google 的神經網路翻譯也是運用這樣的一個概念,每一個翻譯模型並非是自然產生而成,而是需要透過學習,餵養大量的資料與訓練時間才能逐漸完善,不同的語言經過學習之後會轉換成系統容易理解的中間介質語言,因此將兩種語言經過訓練自動學習後,不需要額外的訓練就能自動翻譯另外一種全新的語言。
image source:網路溫度計/記者 葛緯詩攝
以 Google 來說平均一個翻譯模型需要 2 至 3 週的訓練時間,所需餵養的資料量則超過 1 億筆,而這樣的學習模式讓資料量成了深度學習中另一個重要的關鍵因素。
舉例來說,相較於英文翻譯成中文,英文翻譯成法文的準確度要來的高許多,這是因為英國與法國從多年前以來就是雙語並行的國家,因此擁有許多正確可用的資料,反觀英文與中文的可用資料就相對較少,不過近幾年來社群網路的蓬勃發展,慢慢解決了資料量上的問題,現在更重要的是蒐集資料的方法,如何從巨量資料中分辨出雜訊與訊號成了最重要的事情。
以人類的演化情形來看大約每千年會進到下一個階段,而摩爾定律告訴我們電腦的運算能力大約每兩年會成長一倍,巨量資料雖然帶來了更多的可能性,同時卻也產生了更多的雜訊,如同人類史上第一次的資訊革命印刷術的誕生一樣,雖然讓知識存量快速累積,但這些資訊的品質差異也十分的大,如果我們能有一套正確分辨雜訊與資訊的系統,相信以 Google 透過神經網路成功改善翻譯品質的案例來看,更成熟的人工智慧或許就離我們不遠了。


