什麼書會暢銷?「數據分析」結合「機器學習」探勘書市商機!

首圖來源:陳昇瑋提供
資料科學:先搞懂如何發生,再讓它發生
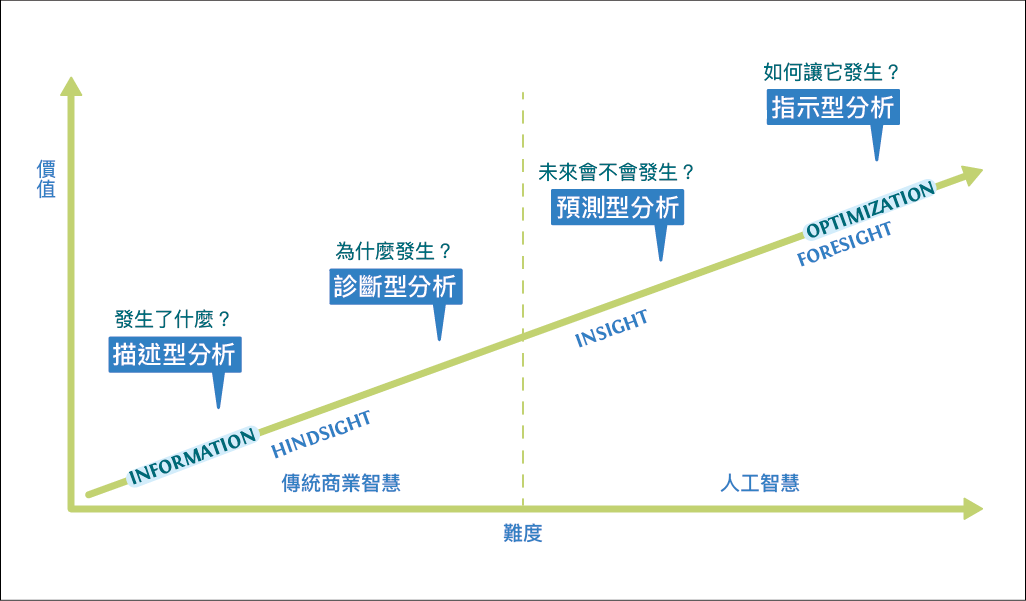 資料分析的四個階段:描述、診斷、預測、指示
資料分析的四個階段:描述、診斷、預測、指示
(image source:Gartner 圖說改編:張語辰)
資料分析並非輸入數據、按下 Enter 鍵,就能得到立即性的結果,其工作至少可分為四個層次:
- 描述:瞭解眼前發生了什麼,例如讀者是什麼樣貌
- 診斷:用電腦來診斷眼前這件事為何發生,例如某些書籍的銷售為什麼特別好
- 預測:未來會不會發生某件事,例如預測新書的銷售表現
- 指示:如何促進某件事在未來發生,例如建置自動薦購系統或上架小工具,幫助提升新書銷售;或是幫書籍做更合適的命名以及封面設計
資料分析跟淘金一樣困難,若沒有以正確的方式使用合適的工具,什麼價值也淘不出來。
分析原始資料就像在砂礫中淘金,雖然不用冒著日曬雨淋的痛苦,但需長時間與電腦折騰,結合數學、統計、機器學習、資料探勘與資料視覺化的專業,整理資料的邏輯,找出隱藏在數據中的含意。若遇到非結構化的資料,在分析前尚需花額外的心力半自動或手動地將之轉換為結構化資料,才能使用分析技術來處理。但正因資料分析可以找出隱藏在數據中的洞察、輔助人類的思維,是一門值得投資心力的科學。
中研院陳昇瑋團隊與博客來合作,將 2014 年 12 月 至 2016 年 3 月間的匿名購書資料,結合政府資料開放平臺的數據,包含各個地區的綜合所得稅申報情況、教育程度、2016 年總統大選得票數等,探討購書行為和讀者生活型態的相關性,將不同購書客群之間的「差異性」數據化,藉以回答誰在買書、買什麼書、什麼書會暢銷……等問題,進而將資料科學的思維引入出版界,讓出版人不用再只是憑著經驗及感覺選書及做書。
什麼人在買什麼書?
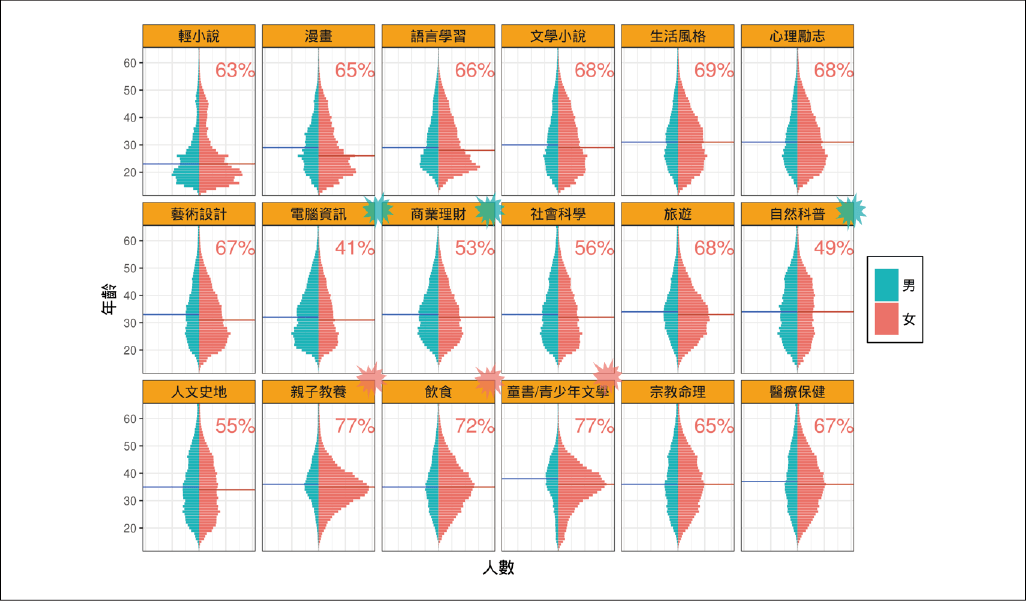 博客來各類購書讀者:性別 x 年齡(資料區間為 2014 年 12 月 至 2016 年 3 月間)
博客來各類購書讀者:性別 x 年齡(資料區間為 2014 年 12 月 至 2016 年 3 月間)
(image source:陳昇瑋提供)
從博客來的匿名消費資料,顯示讀者基本樣貌與購書興趣為:男性較多購買自然科普、電腦資訊和商業理財的書籍,女性較多購買親子教養、飲食、童書和青少年文學。長輩較多購買童書、宗教命理和醫療保健的書籍,而年輕人較多購買輕小說、漫畫和語言學習的書籍。
一樣米養百樣人,一種書也養百種人
在規劃出版與行銷策略時,有一個盲點常被忽略:
不能將同一個書籍類別的讀者,都視為同樣一個族群。
過往看銷售報表與會員資料時,經常會把讀者視為只有一種樣貌:例如財經讀者就是白領階級。但陳昇瑋與團隊定義「差異式讀者樣貌分析」,一層一層深入子類別探勘資料,證實同一個書籍類別亦存在「多重客群」。
以「小說」這個大類別為例,愛看「小說」的不會只是同一群人,例如都是戴著眼鏡的文青。同性愛小說和愛情小說的讀者主要是年輕人,而歷史武俠和文學研究的小說,讀者群以長輩為主。若進一步深入分析武俠小說中的「金庸」這個子類別,更存在兩種主要客群: 15 歲以下的青少年和 40 ~ 50 歲的中年人。
這反應出一個課題:出版與行銷規劃需更分眾、更精準,無論是溝通的宣傳語言、購買的行銷版位,皆需考慮多重客群的存在。
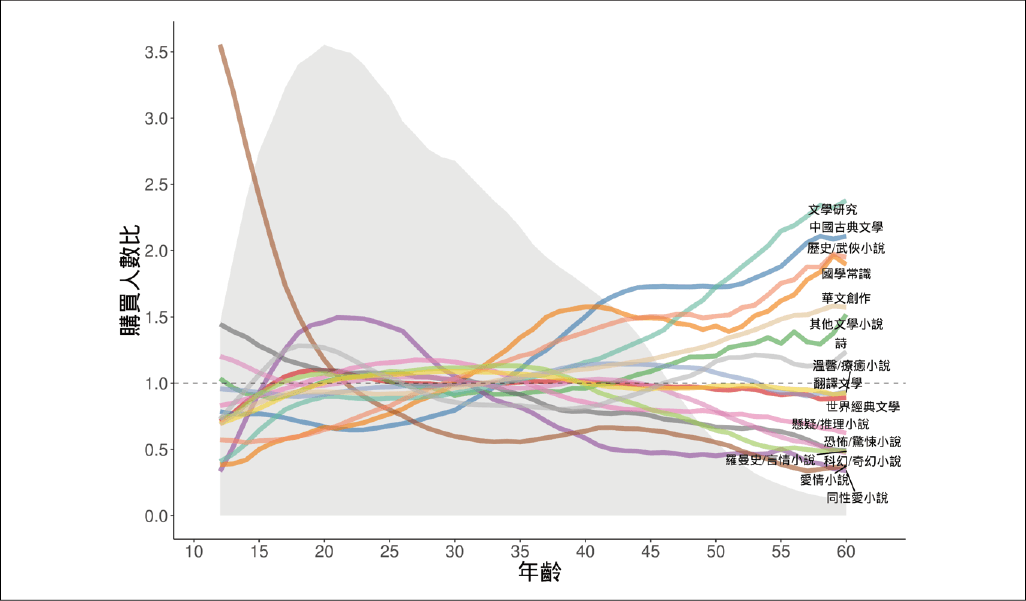 博客來讀者樣貌差異:文學小說類別(資料區間為 2014 年 12 月 至 2016 年 3 月間)
博客來讀者樣貌差異:文學小說類別(資料區間為 2014 年 12 月 至 2016 年 3 月間)
(image source:陳昇瑋提供)


